Rubyconf 2016: The Performance Update

Post-conference haze
Woo! I just got back from RubyConf. It was a great conference
(as usual), and so nice to meet a few of you, my readers,
there. I’ve got a lot to report on the performance front, so
let’s jump right in.
JRuby+Truffle #

Chris Seaton
JRuby+Truffle member Chris Seaton presented an excellent talk
on the problem with C-extensions in Ruby and what he (and
other Ruby implementations) are doing about it.
JRuby+Truffle is a research project, sponsored by Oracle, which combines JRuby with the Graal and Truffle projects. It’s sort of an alternative to the alternative Ruby implementation (JRuby). Though it runs on the JVM, like JRuby, it uses the Truffle language framework to give itself nearly automatic just-in-time compilation and a host of other optimizations. It’s a lot further behind than JRuby in terms of compatibility, but it’s getting there.
C-extensions have always been a problem for alternative Ruby implementations because Ruby’s C API was never clearly defined, so C-extensions essentially just accessed the private internals of MRI. This meant that other Ruby implementations like JRuby had to pretend they were actually MRI to get C-extensions to work.
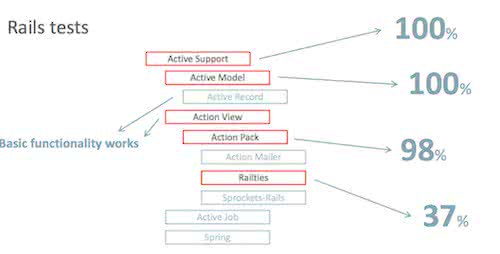
From Chris’ slides.
JRuby+Truffle progress on Rails tests.
I learned alot about the JRuby+Truffle project from Chris’
talk, and, if it can achieve greater compatibility with Rails,
it could be an amazing alternative implementation.
Interestingly, JRuby+Truffle is actually the largest paid Ruby
implementation team, with more paid developers than even MRI!
They’re most of the way to running Rails applications, but
C-extensions (especially Nokogiri and OpenSSL) remain the main
stumbling block. Chris said that almost 25% of all lines of
code in Rubygems are actually C-extensions - ouch!
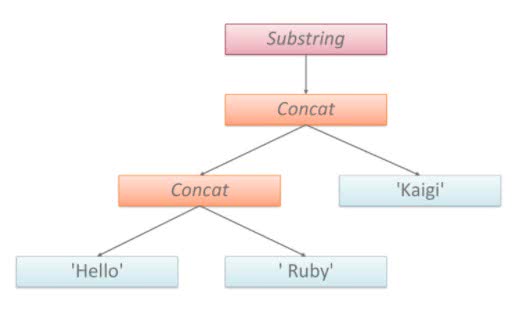
A “rope” style string representation
A lot of the things that the project does are really radical:
see this talk from
Kevin Menard about how JRuby+Truffle represents strings as
ropes, which no other Ruby implementation does. In addition,
because of the way the Graal compiler works in combination
with the
Sulong interpreter, JRuby+Truffle can optimize C code and Ruby code together,
and at the same time. That is, from the compilers perspective,
both Ruby and C code are identical. That’s powerful stuff! All
of this means that, on some specific, limited benchmarks,
JRuby+Truffle can be 30-100x faster than MRI!
Upcoming Changes to CRuby #
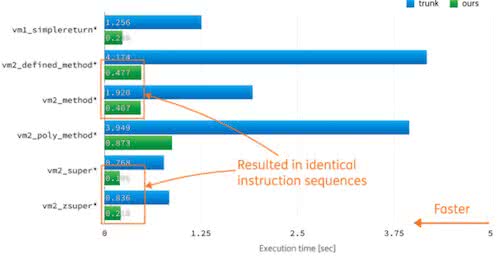
Shyouhei’s slides
showed impressive benchmarks.
Shyouhei Urabe gave a talk about a de-optimizing engine for
CRuby. Basically, compilers can optimize VM instructions when
certain assumptions are made - for example, we can speed up “2
+ 2” if we know “+” is not overridden. To make those
optimizations, though, we also need to de-optimize if someone
does override the “+” operator. JRuby has been doing
this for a long time now, but we’ve never had anything of the
sort in CRuby.
So, since basically anything can be overridden in Ruby, a de-optimizer is actually required before we can start on any optimizations. Shyouhei has proposed one - the details are pretty technical, but you can read more about it here. He showed that in the worst case, it makes a Rails app about 5% slower and uses no additional memory. Of course, the Rails app will be faster (and probably use more memory) once the optimizations are built on top of the de-optimizer.

Aaron cheated at #rubyfriends.
Aaron Patterson gave a great overview of garbage collection
and memory management in Ruby as a prelude to his
optimizations for Ruby’s heap structure. Basically, we can
improve copy-on-write performance and total RSS usage if we
allocate objects into two separate areas - probably old
(objects which won’t be GC’d, like Classes, Modules, etc) and
probably new (everything else). RSS usage on Github improved
by about 10%.
You can see his PR to Github’s Ruby fork here.
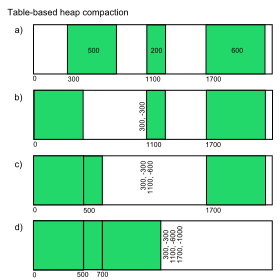
Read more about heap compaction on Wikipedia.
In addition, there was some hallway discussion about a
compacting garbage collector for CRuby. This would be a
very big deal for total memory usage. Previously,
Ruby hasn’t had a compacting GC because C-extensions can hold
memory addresses directly to Ruby objects - moving the object
in memory would cause a segfault. However, Ruby 2.1 introduced
“sunny/shady” objects - sunny objects have never been accessed
by C-extensions, vice versa for shady objects. CRuby
could move sunny objects around the heap to optimize
total memory usage. Aaron Patterson has said on Twitter that
he’s experimenting with it now, and it looks like he’s making
great progress.
Matz clarified the goal of Ruby3x3 (making Ruby “3 times faster”). One of the main ways the core team are measuring that progress is through the optcarrot benchmark. Ruby 3 should run the optcarrot benchmark 3 times faster than Ruby 2.0.
Everything Else #

Another reason to look forward to the next Summer
Olympics.
Don’t look for true static typing in Ruby anytime soon. Matz
said that he thinks type annotations aren’t DRY and aren’t
human-friendly. He did say he liked Crystal though! Instead,
Matz re-iterated his proposal for “soft” or “inferred” types
in Ruby - if the compiler can tell that you’re going to call
to_s
on an object that doesn’t define that method, it will throw an
error. Look for this in Ruby 3 (which Matz has said has a
target release date of “before the Tokyo Olympics in 2020”).
I gave a talk on reducing memory usage in Ruby applications. You can see the slides and notes here. If you purchased the Complete Guide to Rails Performance, there’s probably not much new there to you, but if you haven’t, go buy it!
Evan Phoenix has added myself and Richard Schneeman (of
Heroku) to Puma. We’re going to try to reduce the issue/PR
backlog, but do send us more bug reports if you’re having
trouble with Puma!

It’s hard to read, I know, but Koichi’s shirt really
does say “Kill Threads”.
One interesting aspect of the conference was how much the Ruby
core team (Matz and Koichi, mostly) were hostile to Threads.
Matz said in his opening keynote that in retrospect, he wished
he had never added Thread to Ruby. It seemed like, from a
language designer’s perspective, he thought it was a poor
abstraction and was too difficult to use. Koichi even wore a
“Kill Threads!” shirt while presenting about Guilds, the new
proposed Ruby concurrency model.
Speaking of Guilds, Koichi discussed some more details around the proposed model. GC will remain global and will not be per-Guild. Overhead for creating a new Guild should be extremely low - akin to creating a new Thread. Transferring big objects (like huge Hashes) between Guilds will probably require a new datastructure, like “BigHash” or “BigArray”. Feedback has been very positive to Guilds so far, and many believe it could be just what we need. It seems like we should see Guilds in Ruby some time prior to Ruby 3 - maybe in a few years, so Ruby 2.6 or 2.7.
There was a great talk by Ariel Caplan on the performance issues behind OpenStruct, that oft-forgotten bit of the core library. If, like me, you thought OpenStruct was slow because it invalidated the global method cache, you’re wrong! That was fixed in Ruby 2.1. However, there are plenty more things that slow down OpenStruct, which Ariel discussed in his talk. If you’re interested, checkout his Github repo for a far faster OpenStruct-like implementation.
Colin Jones gave a great talk on DTrace, the performance profiler - here’s his slides. I’ll be digging in to DTrace more in the next few months. It’s an extremely powerful tool.
Two New Community Initiatives #
Finally, there was some great discussion during the Performance Birds of a Feather meeting about various issues. Two big things came out of it - the creation of a Ruby Performance Research Group, and a Ruby Performance community group. Let’s discuss each.
First, the Research Group. Companies with production Ruby applications want faster Ruby, and Ruby implementors want more production data to figure out if the decisions they’re making are making people’s apps faster or slower. While open-source benchmarks exist, they’re often highly synthetic and don’t match real-world usage. And the open-source apps that do exist are limited and may not provide access to the production environment. Additionally, giving any Rails application to a researcher or implementor is a huge pain because setting up even a trivial app can take hours.
So, we proposed the creation of a Research Group. The purpose
of the group would be to allow researches (core team from MRI,
JRuby, JRuby+Truffle, and performance-sensitive projects like
Rails, Sidekiq and Puma) to run limited, small experiments on
production Ruby web applications. These experiments would
produce data, which would be returned back to the researchers.
Some example experiments might be “how often is
object_id
called on objects?” or “how often are global variables set?”.
Experiments may be as simple as installing a Rubygem, or as
complex as using a patched Ruby version. I’m taking the lead
on this project, so expect to hear more before Christmas.
Second, we discussed the need for an open community of Ruby performance enthusiasts. I noted that the CGRP Slack channel (included with the purchase of the course) was already pretty much what was desired. I’m considering opening up the community with a nominal payment (like $5/year) or proof that you’ve had a performance-related PR accepted to Ruby or Rails. You’ll probably hear more from me about that topic soon.
For updates on both of these projects, you’re probably best off subscribing to me newsletter below.
A Great Conference! #
I had a great time at Rubyconf. Plus, who knew downtown Cincinatti had a huge casino? Thanks, ballot initiatives!
Looking forward to seeing all of you at Railsconf in the spring. By the way, did you know the CFP is already open?
Want a faster website?
I'm Nate Berkopec (@nateberkopec). I write online about web performance from a full-stack developer's perspective. I primarily write about frontend performance and Ruby backends. If you liked this article and want to hear about the next one, click below. I don't spam - you'll receive about 1 email per week. It's all low-key, straight from me.
Products from Speedshop
The Complete Guide to Rails Performance is a full-stack performance book that gives you the tools to make Ruby on Rails applications faster, more scalable, and simpler to maintain.
Learn more
More Posts
Organization for Transformative Works Performance Audit
A Rails performance audit report for the Organization for Transformative Works and Archive of Our Own.
Announcing the Rails Performance Apocrypha
I've written a new book, compiled from 4 years of my email newsletter.
We Made Puma Faster With Sleep Sort
Puma 5 is a huge major release for the project. It brings several new experimental performance features, along with tons of bugfixes and features. Let's talk about some of the most important ones.
The Practical Effects of the GVL on Scaling in Ruby
MRI Ruby's Global VM Lock: frequently mislabeled, misunderstood and maligned. Does the GVL mean that Ruby has no concurrency story or CaN'T sCaLe? To understand completely, we have to dig through Ruby's Virtual Machine, queueing theory and Amdahl's Law. Sounds simple, right?