The Practical Effects of the GVL on Scaling in Ruby
The Global Virtual Machine Lock confuses many Rubyists. Most Rubyists I’ve met have a vague sense that the GVL is somehow bad, and has something to do concurrency or parallelism.
(‘CRuby’ refers to the mainline Ruby implementation, written in C. Sometimes people call this ‘MRI’.)‘CRuby’ refers to the mainline Ruby implementation, written in C. Sometimes people call this ‘MRI’. The GVL (formerly known as GIL, as you’re about to learn) is a unique feature to CRuby, and doesn’t exist in JRuby or TruffleRuby.
JavaScript’s popular V8 virtual machine also has a VM lock. CPython also has a global VM lock. That’s three of the most popular dynamic languages in the world! VM locks in dynamic languages are very common.
(Instead of removing the GVL, Ruby core has signaled that it will take an approach similar to V8 Isolates with inspiration from the Actor concurrency model (discussed at the end).)Instead of removing the GVL, Ruby core has signaled that it will take an approach similar to V8 Isolates with inspiration from the Actor concurrency model (discussed at the end).
Understanding CRuby’s Global VM Lock is important when thinking about scaling Ruby applications. It will probably never be removed from CRuby completely, and its behavior changes how we scale Ruby apps efficiently.
Understanding what the GVL is and why the current GVL is “global” will help you to answer questions like these:
- What should I set my Sidekiq concurrency to?
- How many threads should I use with Puma?
- Should I switch to Puma or Sidekiq from Unicorn, Resque, or DelayedJob?
- What are the advantages of event-driven concurrency models, like Node?
- What are the advantages of a global-lock-less language VM, like Erlang’s BEAM or Java’s JVM?
- How will Ruby’s concurrency story change in Ruby 3?
We’ll deal with these questions and more in this article.
What we’re locking: the language virtual machine #
(Most descriptions of the GVL immediately dive into concepts like atomicity and thread-safety. This description will start from a more basic premise and work up to that.)Most descriptions of the GVL immediately dive into concepts like atomicity and thread-safety. This description will start from a more basic premise and work up to that.
(YARV was essentially Koichi Sasada’s graduate thesis.)YARV was essentially Koichi Sasada’s graduate thesis.
Wait: isn’t it the GIL? What’s the GVL?
GIL stands for Global Interpreter Lock, and it’s something that was removed from Ruby (or just mutated, depending on how you look at it) in Ruby 1.9, when Koichi Sasada introduced YARV (Yet Another Ruby VM) to Ruby. YARV changed CRuby’s internal structure so that the lock existed around the Ruby virtual machine, not an interpreter. The correct terminology for over a decade now has been GVL, not GIL.
(You can interact with instruction sequences via the InstructionSequence class. Everything is an object in Ruby!)You can interact with instruction sequences via the InstructionSequence class. Everything is an object in Ruby!
How does an interpreter differ from a virtual machine?
A virtual machine is a little like a CPU-within-a-CPU. Virtual machines are computer programs that usually take simple instructions, and those instructions manipulate some internal state. A Turing machine, if it was implemented in software, would be a kind of virtual machine. We call them virtual machines and not machines because they’re implemented in software, rather than in hardware, like a CPU is.
Before Ruby 1.9, Ruby didn’t really have a separate virtual machine step - it just had an interpreter. As your Ruby program ran, it actually interpreted each line of Ruby as it went. Now, we just interpret the code once, turn it into a series of VM instructions, and then execute those instructions. This is much faster than interpreting Ruby constantly.
A Turing machine, implemented in software, would be
a kind of virtual machine.
Wikimedia Commons by RosarioVanTuple
The Ruby Virtual Machine understands a simple instruction set. Those instructions are generated from the Ruby code you write by the interpreter, and then the virtual machine instructions are fed into the Ruby VM.
Let’s watch this in action. First, in case you didn’t know, you can execute Ruby from the command line using the -e option:
$ ruby -e "puts 1 + 1"
2

Now, you can then dump the instructions for this simple
program by calling
--dump=insns:
$ ruby --dump=insns -e "puts 1 + 1"
== disasm: #<ISeq:<main>@-e:1 (1,0)-(1,10)> (catch: FALSE)
0000 putself ( 1)[Li]
0001 putobject_INT2FIX_1_
0002 putobject_INT2FIX_1_
0003 opt_plus <callinfo!mid:+, argc:1, ARGS_SIMPLE>, <callcache>
0006 opt_send_without_block <callinfo!mid:puts, argc:1, FCALL|ARGS_SIMPLE>, <callcache>
0009 leave
Ruby is a “stack-based” VM. You can see how this works by
looking at the generated instructions here - we add the
integer 1 to the stack two times, than call
plus. When
plus
is called, there are two integers on the stack. Those two
integers are replaced by the result, 2, which is then on the
stack.
So, what does the Ruby VM have to do with threading, concurrency and parallelism?
Concurrency and Paralellism #
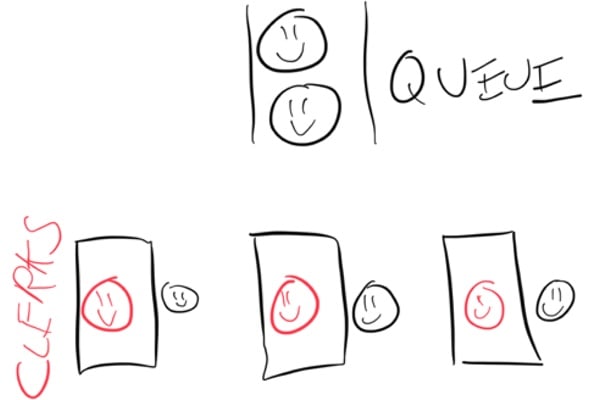
You may be aware that there’s a difference between concurrency and parallelism. Imagine a grocery store. At this grocery store, we have a line and some checkout clerks working to pull customers from the line and get their groceries checked out.
Each of our grocery store checkout clerks works in parallel. They don’t need to talk to each other to do their job, and what one clerk is doing doesn’t affect the other in any way. They’re working 100% in parallel.
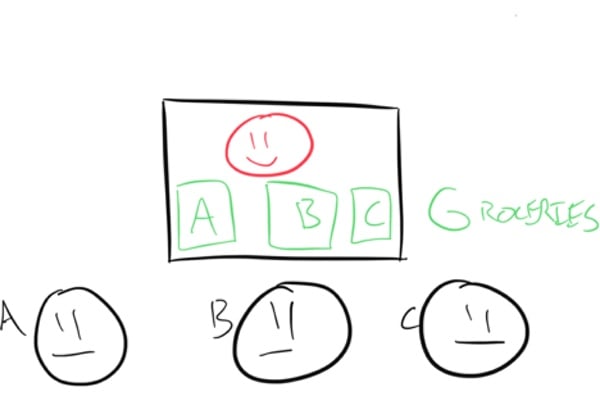
Now, a clerk can work on multiple customers concurrently. This would look like a clerk grabbing multiple customers from the line, working on one customer’s groceries for a moment, then switching to another customer’s groceries, and so on. This would be working concurrently.
Let’s take a more concrete example. Compare three grocery store clerks working in parallel with a single one working concurrently. To check out a customer, we must perform two operations: scanning their groceries, and then bagging them. Imagine each customer’s groceries take the exact same amount of time to scan and bag.
Three customers arrive. Let’s say scanning takes time
A
and bagging takes time
B.
Our three parallel clerks will process these three customers
in time
(A + B).
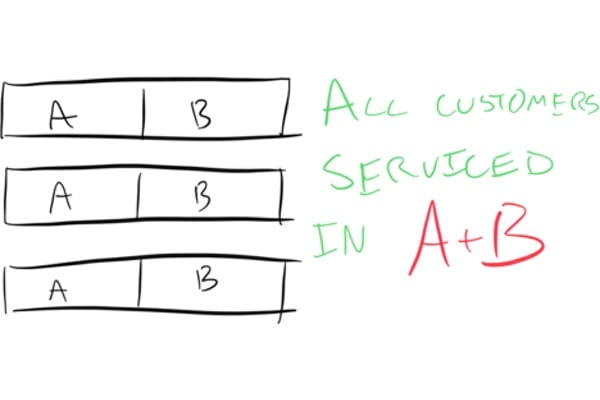
The parallel case.
What about our concurrent clerk? All three of her customers arrive at the same time. The clerk scans each customer’s groceries, then bags each customer’s groceries. Each customer is worked on concurrently, but never in parallel.
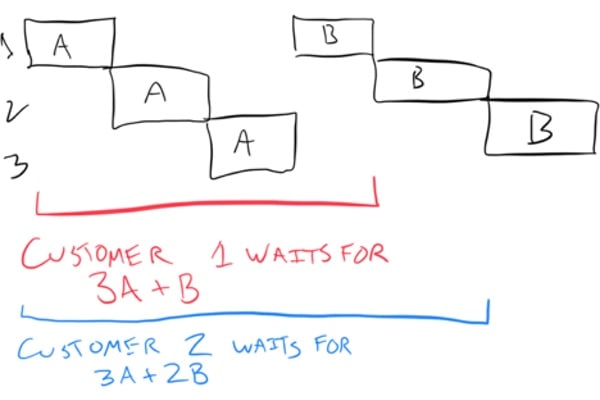
The concurrent case.
In the concurrent case, our first customer experiences a total
service time of
(3A + B). They had to wait for everyone else’s groceries to be
checked out for their own groceries to get bagged. The second
customer will exerience a total service time of
(3A + 2B), and the final customer will experience a service time of
(3A + 3B).
Notice how the customers who got the concurrent checkout clerk experienced a longer total service time than the customers who used our three parallel clerks.
In short: concurrency is interesting, but parallelism is what speeds up systems and allows them to handle increased load.
Performing two operations concurrently means that the start and end times of those operations overlapped at some point. For example, you and I sit down to a sign a contract. However, there is only one pen. I sign where I’m supposed to, hand the pen to you, and then you sign. Then, you hand the pen back to me and I initial a few lines. You might say that we signed the contract concurrently, but never in parallel - there was only one pen, so we couldn’t sign the contract at the exact same time.
Peforming operations in parallel means that we are doing those operations at the exact same instant. In my contract example, a parallel contract signing would involve two pens (and probably two copies of the contract, otherwise it would get a little crowded).
Concurrency and Paralellism on a Computer #
On a modern operating system, programs are run with a combination of processes and threads. Processes have at least one thread, and can have up to thousands.
To extend the grocery store analogy, processes are like the checkout counters that our clerks use. They contain tools and common resources, like the point-of-sale terminal and the barcode scanner, but they don’t actually do anything. A process usually contains a memory allocation (the heap), file descriptors (sockets, files, etc), and other such computer resources.
Threads actually run our code. Each process has at least one thread. In our analogy, they’re like the store clerks. They also hold a small amount of information. For example, if we’re adding two local variables in a Rails application, our thread contains information about those two variables (thread-local storage) and also what line of code we’re currently running (the stack).

Threads run the code when they are scheduled to by the operating system’s kernel. The Ruby runtime itself doesn’t actually manage when threads are executed - the operating system decides that.
When Ruby was written in the 90s, all processes had just one thread. This started to change in the early 2000s, necessitating the rewrite of the language VM in Ruby 1.9 (YARV), which is what gave us the GVL as we know it today.
What the GVL actually does #
As mentioned earlier, the Ruby Virtual Machine is what actually turns Ruby virtual machine instructions (generated by the interpreter) into CPU instructions.

The Ruby Virtual Machine is not internally thread-safe. If two threads try to access the Ruby VM at the same time, really Bad Things would happen. This is a bit like the point of sale terminal at our grocery store checkout counters. If two checkout clerks tried to use the same POS terminal, they would interrupt each other and probably keep losing their work or corrupting each other’s work. You would end up paying for someone else’s groceries!
So, because it isn’t safe for multiple threads to access the Ruby Virtual Machine at the same moment, instead we use a global lock around it so that only one thread can access it in parallel.
(One caveat of the Javascript GVL is that it isn’t actually global: you can create additional Isolates. Koichi Sasada’s proposal for Ractors (formerly Guilds) would be similar.)One caveat of the Javascript GVL is that it isn’t actually global: you can create additional Isolates. Koichi Sasada’s proposal for Ractors (formerly Guilds) would be similar.
It is extremely common for dynamic language VMs to not be thread-safe. As mentioned, CPython and V8 are the most prominent examples. Java is probably the best example of a semi-dynamic language that does have a threadsafe VM. It’s also why so many languages are written on top of the JVM: writing your own threadsafe VM is really hard.

TFW you realize that there’s always going to be
locks, the only difference is what level they’re implemented
at and who implements them
There’s a few good reasons that having a GVL is so popular:
- It’s faster. Single-threaded performance improves because you don’t have to constantly lock and unlock internals.
- Integrating with extensions, such as C extensions, is easier.
- It’s easier to write a lockless VM than one with a lot of locks.
Each Ruby process has its own Global VM Lock, so it might be more accurate to say that it’s a “process-wide VM lock”. Its “global” in the same sense that a “global variable” is global.
Only one thread in any Ruby process can hold the global VM lock at any given time. Since a thread needs access to the Ruby Virtual Machine to actually run any Ruby code, effectively only one thread can run Ruby code at any given time.

Let me play you the song of my people:
“GGVVVVLLLLLLLLLLLLLLLL”
Think of the GVL like the conch shell in the Lord of the Flies - if you have it, you get to speak (or execute Ruby code in this case). If the GVL is already locked by a different thread, other threads must wait for the GVL to be released before they can hold the GVL.
Amdahl’s Law: Why 1 Sidekiq Process Can Be 2x as Efficient as DelayedJob or Resque #
Your programs actually do many things that don’t need to access the Ruby Virtual Machine. The most important is waiting on I/O, such as database and network calls. These actions are executed in C, and the GVL is explicitly released by the thread waiting on that I/O to return. When the I/O returns, the thread attempts to reacquire the GVL and continue to do whatever the program says.
This has enormous real-world performance impacts.
Imagine you have a stack of satellite image data you have to
process (with Ruby). You have written a Sidekiq job, called
SatelliteDataProcessorJob, and each job works on a small fraction of all of the
satellite data.
class SatelliteDataProcessorJob
include Sidekiq::Worker
def perform(some_satellite_data)
process(some_satellite_data)
touch_external_service(some_satellite_data)
add_data_to_database(some_satellite_data)
end
end
Let’s imagine that
process
is a 100% Ruby method, which does not call C extensions or
external services. Further, let’s imagine that
touch_external_service
and
add_data_to_database
are effectively 100% I/O methods that spend all of their time
waiting on the network.
First, an easy question: if each run of
SatelliteDataProcessorJob
takes 1 second, and you have 100 enqueued jobs and just 1
Sidekiq process with 1 thread, how long will it take to
process all the jobs? Assume infinite CPU and memory
resources.
100 seconds.
How about if you two processes? 50 seconds. And 25 seconds for 4 processes and so on. That’s parallelism.
Now, let’s say you have 1 Sidekiq process with 10 threads. How long will it take to process all of those jobs?
The answer is it depends. If you’re on JRuby or TruffleRuby, it will take about 10 seconds, because each thread is fully parallel with all the other threads.
But on MRI, we have the GVL. Does adding threads increase concurrency?

{kind=link}
{kind=link}
It turns out, this exact problem interested computer scientist Gene Amdahl back in 1967. He proposed something called Amdahl’s Law, which gives the theoretical speedup in latency for the execution of tasks with fixed workloads when resources increase.
Amdahl figured out that the speedup you got from additional parallelism was related to the proportion of execution time that could be done in parallel. Sound familiar?
Amdahl’s Law is simply
1 / (1 - p + p/s), where
p is
the percentage of the task that could be done in parallel, and
s is
the speedup factor from the part of the task that gained
improved resources (the parallel part).
So, in our example, let’s say that half of
SatelliteDataProcessorJob
is GVL-bound and half is IO-bound. In this case,
p is
0.5
and
s is
10, because we can wait for IO in parallel and there are 10
threads.
In this case, Amdahl’s Law shows that a Sidekiq process
would go through our jobs up to 1.81x faster than a
single-threaded Resque or DelayedJob process.
Many background jobs in Ruby spend at least 50% of their time waiting on IO. For those jobs, Sidekiq can lead to a 2x decrease in resource usage, because 1 Sidekiq process can do the work of what used to take 2 single-threaded processes.
So, even with a GVL, adding threads to applications increases throughput-per-process, which in turn lowers memory consumption.
Threads, Puma and GVL-caused Latency #
This also means that “how many threads does my Sidekiq or Puma process need” is a question answered by “how much time does that thread spend in non-GVL execution?” or “how much time does my program spend waiting on I/O?” Workloads with high percentages of time spent in I/O (75%+ or more) often benefit from 16 threads or even more, but more typical workloads see benefit from just 3 to 5 threads.

It’s possible to configure your thread pools to be too large. Setting Puma or Sidekiq to thread settings higher than 5 can lead to contention for the GVL if the work is not parallelizable enough. This increases service latency.
While total time to process all of the units of work remains the same, the latency experienced by each individual unit of work increases.
Imagine a grocery store where a checkout clerk grabbed 16
people off of the checkout queue and checked those 16 people’s
groceries concurrently, scanning one item per person before
scanning one item from the next person’s cart. Rather than
experiencing checkout time as
(A + B), they experience a checkout time of
16(A+B).
(This effect is generally present in a concurrent-but-not-100%-parallel system where overall utilization is not extremely high. We’re mitigating this effect slightly in Puma 5 by having Puma workers with more than one thread delay listening to the socket, so less-loaded workers pick up requests first.)This effect is generally present in a concurrent-but-not-100%-parallel system where overall utilization is not extremely high. We’re mitigating this effect slightly in Puma 5 by having Puma workers with more than one thread delay listening to the socket, so less-loaded workers pick up requests first.
Some people misidentify this additional latency as “context switching” costs. However, latency experienced by the individual unit of work is increasing without additional switching cost.
In any case, context switching on modern machines and operating systems is pretty cheap relative to the time it takes to service a typical web app request or background job. It does not add hundreds of milliseconds to response times - but oversaturating the GVL can.
If adding threads to a CRuby process can increase latency, why is it still useful?
(Shouldn’t adding an additonal thread only increase memory usage by 8MB, which is the size of the thread’s stack allocation? Ah, if only memory usage was that simple. Learn more about the complexities of RSS and thread-induced fragmentation here.)Shouldn’t adding an additonal thread only increase memory usage by 8MB, which is the size of the thread’s stack allocation? Ah, if only memory usage was that simple. Learn more about the complexities of RSS and thread-induced fragmentation here.
Adding more threads to a Ruby process helps us to improve CPU utilization at less memory cost than an entire additional process. Adding 1 process might use 512MB of memory, but adding 1 thread will probably cause less than 64MB of additional memory usage. With 2 threads instead of 1, when the first thread releases the GVL and listens on I/O, our 2nd thread can either pick up new work to do, increasing throughput and utilization of our server.
GitLab switched from Unicorn (single-thread model) to Puma (multi-thread model) and saw a 30% decrease in memory usage across their fleet. If you’re memory-constrained on your host, this allows you to run 30% more throughput for the same money. That’s awesome.
The Future #
For a decade now, bystanders have declared that Ruby is dead because it “doesn’t have a proper concurrency story”.
I think we’ve shown that there is a concurrency story in Ruby. First, we have process-based concurrency. We multiply GVLs by multiplying processes. This works perfectly fine, if you have enough memory.
If you’re out of memory, you can use Sidekiq or Puma, which provides a threaded container for our apps, and then let pre-emptive threading do its thing.
Ruby has proven that process-based concurrency (which is really what the GVL forces us to do) scales well. It’s not much more expensive than other models, especially these days when memory is so cheap on cloud providers. Think critically about what an Actor-style approach or an Erlang Process-style approach would actually change about your deployment at the end of the day: you would use less memory per CPU. But on large deployments, most web applications are already CPU-bottlenecked, not memory!
Ractor #
Koichi Sasada, author of YARV, is proposing a new concurrency abstraction for Ruby 3 called Ractors. It’s a proposal based on the Actor concurrency model (hence Ruby Actor -> Ractor). Basically, Actors are boxes for objects to go into, and each actor can only touch its own objects, but can send and receive objects to/from other Actors. Here’s an example written by Koichi Sasada:
r = Ractor.current
rs = (1..10).map{|i|
r = Ractor.new r, i do |r, i|
r.send Ractor.recv + "r#{i}"
end
}
r.send "r0"
p Ractor.recv #=> "r0r10r9r8r7r6r5r4r3r2r1"
Eventually (not yet in the current implementation), each Ractor will get their own VM lock. That means the example code above will execute in parallel.
This is made possible because Ractors don’t share mutable state. Instead, they only share immutable objects, and can send mutable objects between each other. This should mean that we don’t need a VM lock inside of a Ractor.
Koichi Sasada’s Ractor proposal is now public, though as of this writing the docs are mostly in Japanese, and “each Ractor gets its own VM lock” has not yet been implemented. Ractors will essentially allow us to “multiply” GVLs in a process, which would make the GVL no longer “global”, although the lock will still exist in each Ractor. The Global VM Lock will become a Ractor VM Lock.
TL:DR; #
Thanks for listening to me whinge. Here’s what you need to remember:
- If you are memory bottlenecked on Ruby, you need to saturate the GVL by adding more threads, which will allow you to get more CPU work done with less memory use.
- The GVL means that parallelism is limited to I/O in Ruby, so switch to a multithreaded background job processor before you switch to a multithreaded web server. Also, you’ll probably use much higher threadpool sizes with your background jobs than with your web server.
- Ruby 3 might make the GVL no longer global by allowing you to multiply VMs using Ractors. Application servers and background job processors will probably change their backend to take advantage of this, you won’t really have to change much of your code at all, but you will no longer have to worry about thread safety (yay).
- Process based concurrency scales very well, and while it might lose a few microseconds to other concurrency models, these concurrency switching costs generally don’t matter for the typical Rails application. Instead, the important thing is saturating CPU, which is the most scarce resource in today’s computing environments.
Want a faster website?
I'm Nate Berkopec (@nateberkopec). I write online about web performance from a full-stack developer's perspective. I primarily write about frontend performance and Ruby backends. If you liked this article and want to hear about the next one, click below. I don't spam - you'll receive about 1 email per week. It's all low-key, straight from me.
Products from Speedshop
The Complete Guide to Rails Performance is a full-stack performance book that gives you the tools to make Ruby on Rails applications faster, more scalable, and simpler to maintain.
Learn more
More Posts
Organization for Transformative Works Performance Audit
A Rails performance audit report for the Organization for Transformative Works and Archive of Our Own.
Announcing the Rails Performance Apocrypha
I've written a new book, compiled from 4 years of my email newsletter.
We Made Puma Faster With Sleep Sort
Puma 5 is a huge major release for the project. It brings several new experimental performance features, along with tons of bugfixes and features. Let's talk about some of the most important ones.
The World Follows Power Laws: Why Premature Optimization is Bad
Programmers vaguely realize that 'premature optimization is bad'. But what is premature optimization? I'll argue that any optimization that does not come from observed measurement, usually in production, is premature, and that this fact stems from natural facts about our world. By applying an empirical mindset to performance, we can...