Why Your Rails App is Slow: Lessons Learned from 3000+ Hours of Teaching

“What I do have is a particular set of skills, a set
of skills which makes me a nightmare for slow Rails
applications like you.”
For the last 4 years, I’ve been working on making Rails applications faster and more scalable. I teach workshops, I sell a course, and I consult. If you do anything for a long period of time, you start to see patterns. I’ve noticed four different factors that prevent software organizations from improving the performance of their Rails applications, and I’d like to share them here.
Performance becomes a luxury good, especially when no one is watching #
Often times at my workshops, I discover that an attendee simply has no visiblity into what their application is doing in production - they either don’t understand their dashboards, they don’t have them, or they’re not allowed to even access them (“DevOps team only”).
Performance metrics are often just not tracked. No one is aware if the app is over or underscaled, no one knows if the app is “slow” or “fast”. Is it any wonder, then, that no one spends any time working on it?
Performance is rarely the first priority of any organization, and often gets “trickled down” hours and resources.

Some of this is actually a good thing. There’s a reason that the classic programming mantra of “make it work, make it clean, make it fast” is in that order and not the opposite way around. People pay for software that does stuff. If it does that stuff quickly and in a pleasantly performant way, then that’s great, but it’s not always required (especially if the organization is first to market in their space and customers have no other options).
Often, my consulting clients are at a point in their organization where they’re no longer scraping by on ramen and cheeto dust, but have a solid business that’s expanding (slowly or quickly). They’ve finally gotten their heads above water and they’re ready to start thriving, not just surviving. People don’t come to me when they’re still trying to achieve product market fit unless things have become untenable, and then that’s more of a rescue job.

When the time comes to set the budget on performance
instead of feature velocity.
This is a natural and correct progression. It also means organizations accumulate performance debt during that initial period of building and obtaining product-market fit. I think there may be some that believe that all kinds of technical debt are some kind of sinful black stain on any organization, and that if you just Coded The Right Way or were a Software Craftsperson™ this would not have happened. I think that’s probably wrong. Before achieving ramen profitability, businesses must take out technical debt as a kind of financing of their own product development runway. This will happen regardless of one’s coding techniques or knowledge level.

However, performance is not a luxury good. It isn’t something that can simply be ignored until one’s organization has a spare four or five figures in the couch cushions. Like technical debt, there is a point when feature work grinds to a halt because the organization is too busy maintaining the performance debt that has accrued. Requests are timing out. Customers are complaining about slow the app feels and switching to competitors. You’re scared to check the AWS bill.
Ideally, organizations monitor and sensibly take out performance debt when required, and understand the full extent of the work that must be done in the future.
To do this sort of “sensible debt accrual”, you need performance monitoring/metrics and you need to understand how to present numbers to management. I find that while most people know subscribe to a performance monitoring service, such as New Relic, Skylight or Scout, they often have no idea how to read it and extract useful insights from it, making it a very expensive average latency monitor. Being able to actually use your APM is a critical performance skill that I cover in great detail in my workshops and course.
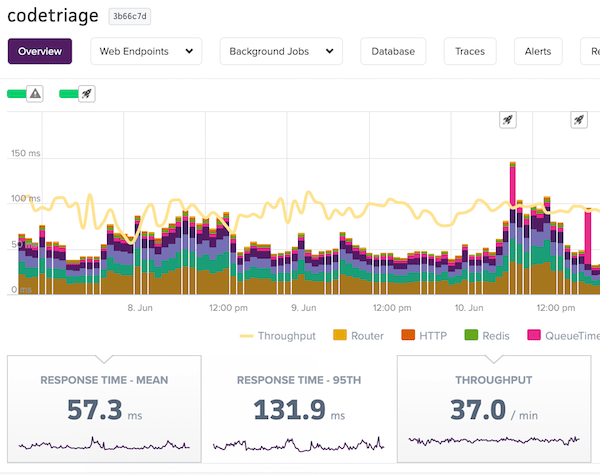
If you can’t draw insights from this, you’re just
throwing cash out the door.
Monitoring these metrics allows you to assess where you’re at and to figure out what parts of the application have accrued performance debt. It also helps you to make decisions on the “cost/benefit” of future work.
It also means you need to be able to “speak manager” or “speak business”. The business case for adding more features is obvious to the non-technical side of your organization. There is a great business case for performance, fortunately, both from the side of the customer and from the cost side as well - reducing average latency by 50% means you can spend 50% less on your application’s servers thanks to queueing theory and something called Little’s Law.
At my workshops, I spend a lot of time simply discussing terminology, like request queueing, latency, throughput, tracing and profiling. Giving people the vocabulary they need to understand the tools out there seems to be half the battle of getting everyone comfortable reading their own metrics.
Complex apps and complex problems, with little training #
This leads me to the second cause of performance problems in software - a simple lack of knowledge. We can’t optimize what we don’t understand and we can’t fix what we can’t see.
I wrote the Complete Guide to Rails Performance simply because there was so much information about this topic that had simply never been compiled before into one place.
“What’s request queueing?”
This shows itself most when scaling for throughput. Most organizations simply aren’t tracking critical scaling metrics or even know what they are, often because they believe the platform-as-a-service that they’re using should “take care of this” for them. By the time I’ve been called in, they’re spending thousands of dollars a month more than they need to, and could have fixed this months or even years ago with some simple autoscaling policies and a bit of organizational knowledge around scaling. Or, the flipside is happening and they’re massive under-scaled, with 25-50% of their total request latency being just time spent queueing for resources.
Performance work is not rocket science. However, unlike a lot of other areas in software1 (The only other area in software that requires an even wider base of knowledge is security. Consider Rowhammer - basically an electrical engineering exploit in very particular configurations of DRAM.)1 The only other area in software that requires an even wider base of knowledge is security. Consider Rowhammer - basically an electrical engineering exploit in very particular configurations of DRAM., it can require an extremely broad base of knowledge. When your customer says the site “feels slow”, the problem can quite reasonably be almost anywhere between the pixels on the user’s screen (say, an issue with the customer’s client machine) and the electrons running through the silicon on your cloud service provider (for example, a mitigation for a recent Intel security issue puts your servers above capacity). Feature work and even to a large extent refactoring work generally only requires knowledge of the language and frameworks in use. Performance work often needs esoteric knowledge from other fields (such as queueing theory) in addition to highly in-depth knowledge in your frameworks and language.2 (I wrote a 3000+ word blog about the critical performance differences between English-language synonyms .present? and .exists? in Rails, for example, but my Rails performance course spends the majority of the time talking about things which are not Ruby-specific.)2 I wrote a 3000+ word blog about the critical performance differences between English-language synonyms .present? and .exists? in Rails, for example, but my Rails performance course spends the majority of the time talking about things which are not Ruby-specific.

Looking at a flamegraph of a Rails app for the first
time often leads to this reaction.
This depth of knowledge simply isn’t present in many organizations, especially those who place sprint velocity before the development of engineering capacity and skills in the organization.
The workshops I’ve been doing have really allowed me to go in deep on complex problems and help people deal with the “wrinkles” introduced by their application. Getting to look over people’s shoulders while they experience an error or something I hadn’t anticipated has been very rewarding, both for them and for me as an educator.
Also, during those workshops, I don’t emphasize “pre-baked” problem/solutions, but instead have the attendees bring their real world applications, and we immediately try to apply what we’ve learned on their actual apps right then and there. I don’t want anyone to go home and run into a problem caused by the complexity of their app - rather, I’d like that to happen while we’re both in the same room!
Boiling frogs - even when tracked, performance slips without fix #
In the Slack channel for the Complete Guide to Rails Performance, we’ve had a few conversations about managing performance work in the software organization.

Walking into the office on Monday like
An organizational culture that always places completeness over quality inevitably runs into issues. Often when I get new clients, they’re experiencing not just performance issues but have problems with all the various dimensions of software quality: low correctness (an excess of bugs and lack of test coverage), high complexity (“technical debt”, spaghetti organization), and a poor deployment pipeline (broken builds, janky deploys). These aspects of software quality tend to either all be good or all be bad. Project management can (and often should) sacrifice quality for a period of time to prioritize completeness and features, but when it’s done pathologically, it inevitably leads to ruin.
I find that the lack of software quality culture often arises because no one is measuring it3 (I actually really don’t vibe with the ‘software craftsperson’ aesthetic that people like Uncle Bob try to push. Quality is great but it isn’t everything. It’s possible to turn this into navelgazing, and building ivory towers.)3 I actually really don’t vibe with the ‘software craftsperson’ aesthetic that people like Uncle Bob try to push. Quality is great but it isn’t everything. It’s possible to turn this into navelgazing, and building ivory towers.. Feature velocity is measured, or at least vaguely tracked, with things like pull request counts, sprint points, or user stories. We shipped 5 stories last week, so management expects us to ship 5 this week.
Fortunately, many software quality measures are actually very easy to track. How many bugs were reported or experienced by customers last week? How much downtime did we have? How many deploys were there? Are these numbers rising or falling?
In terms of performance, most organizations would benefit from setting simple thresholds that, if exceeded, move performance work into the “bug fixing” pipeline that the organization employs. For example, an organization can commit to a maximum 95th percentile latency of 1 second. If a transaction4 (In New Relic parlance - a single controller action is a ‘transaction’.)4 In New Relic parlance - a single controller action is a ‘transaction’. exceeds that threshold, a new bug is recorded.
For organizations that want to improve the customer’s experience and perceived performance of the application, other budgets may be necessary. For example, a first-page-load time of 5 seconds. This page load target has implications that flow down throughout the stack, as one simply cannot ship 10 megabytes of JavaScript and also have a page load in 5 seconds5 (In fact, I would estimate that to keep page load times below 5 seconds on the average connection and hardware, you can probably ship only a few hundred KB)5 In fact, I would estimate that to keep page load times below 5 seconds on the average connection and hardware, you can probably ship only a few hundred KB.
Software engineers are often poor communicators, and they very often fail to communicate to other parts of the organization that prioritizing feature velocity at all costs is not sustainable.
Think of it this way: how do you think the project managers in your organization would answer the following questions?

Bezos showering in your AWS bill
- Is your tolerance for the slowness of our application infinite? (i.e. can the app just beachball for all customers all the time?)
- Do you have infinite money to spend on our EC2 instance bills?
If the answer to either of those questions is “no”, then it is your job as a software developer to find and make explicit those tolerances. They will be different for every organization. These performance requirements can be easily translated into automated alerts and thresholds.
You just have to have the conversation beforehand. The difference between “Hey boss - we’ve been shipping 12 points a week for the last 8 weeks and now we can’t ship anything for 6 weeks because we need to write tests and make the homepage load time somewhat bearable” and “we exceeded the limit for page load time that we all agreed upon 6 months ago, and we’ll need to reduce velocity for a while to compensate” is miles apart.
As a result of seeing this pattern often enough, I’ve changed how I phrase my consulting deliverables, as I now realize I need to provide ammunition for the engineers when bringing back my recommendations to the “business side”.
It’s not Ruby, and it isn’t (really) Rails #

LEAVE MATZ ALONE
And, finally, here’s what isn’t the reason why your web application is slow: your framework or language choice. Once 90th percentile latency is lower than 500 milliseconds and median latency is below 100 milliseconds, most web application backends are no longer the bottleneck in their customer’s experience (if they ever were to begin with, which, in the age of 10 megabyte JavaScript bundles, they are usually not).
It’s 2017 and web applications don’t return flat HTML files anymore5 (CNN.com took 5MB of resources and 112 requests to render for me, today. R.I.P. the old light web.)5 CNN.com took 5MB of resources and 112 requests to render for me, today. R.I.P. the old light web.. Websites are gargantuan, with JavaScript bundles stretching into the size of megabytes and stylesheets that couldn’t fit in ten Apollo Guidance Computers. So how much of a difference does a web application which responds in 1 millisecond or less make in this environment?
Vanishingly little. Nowadays, the average webpage takes 5 seconds to render. Some JavaScript single-page-applications can take 12 seconds or more on initial render.
Server response times simply make up a minority part of the actual user experience of loading and interacting with a webpage - cutting 99 milliseconds off the server response time just doesn’t make a difference.
Not to mention: if Ruby on Rails, frequently maligned “as too slow” or “can’t scale”, can run several of the top 1000 websites in the world by traffic, including that little fly-by-night outfit called GitHub, then it’s a fine choice for whatever your application is. Rails is just an example here - there are many comparable frameworks in comparable languages that you could substitute like Python and Django. There are some web applications for which 100 milliseconds of latency is an unacceptable eon (advertising is the most common case), but for the vast majority of us delivering HTML or JSON to a client, that’s zippy quick.
Whither Rails Today? #
One of the questions I ask in my post-workshop survey is “How do you feel writing Ruby on Rails? Would you like to keep doing it?”.
The answers I get back are always astoundingly positive. For all the FUD on the web at large, people writing Ruby are incredibly happy doing it. And that’s what keeps me writing and teaching: as long as people feel that performance concerns are keeping them from enjoying Ruby or choosing it as their tech stack, I’ll keep doing what I do.
Want a faster website?
I'm Nate Berkopec (@nateberkopec). I write online about web performance from a full-stack developer's perspective. I primarily write about frontend performance and Ruby backends. If you liked this article and want to hear about the next one, click below. I don't spam - you'll receive about 1 email per week. It's all low-key, straight from me.
Products from Speedshop
The Complete Guide to Rails Performance is a full-stack performance book that gives you the tools to make Ruby on Rails applications faster, more scalable, and simpler to maintain.
Learn more
More Posts
Organization for Transformative Works Performance Audit
A Rails performance audit report for the Organization for Transformative Works and Archive of Our Own.
Announcing the Rails Performance Apocrypha
I've written a new book, compiled from 4 years of my email newsletter.
We Made Puma Faster With Sleep Sort
Puma 5 is a huge major release for the project. It brings several new experimental performance features, along with tons of bugfixes and features. Let's talk about some of the most important ones.
The Practical Effects of the GVL on Scaling in Ruby
MRI Ruby's Global VM Lock: frequently mislabeled, misunderstood and maligned. Does the GVL mean that Ruby has no concurrency story or CaN'T sCaLe? To understand completely, we have to dig through Ruby's Virtual Machine, queueing theory and Amdahl's Law. Sounds simple, right?